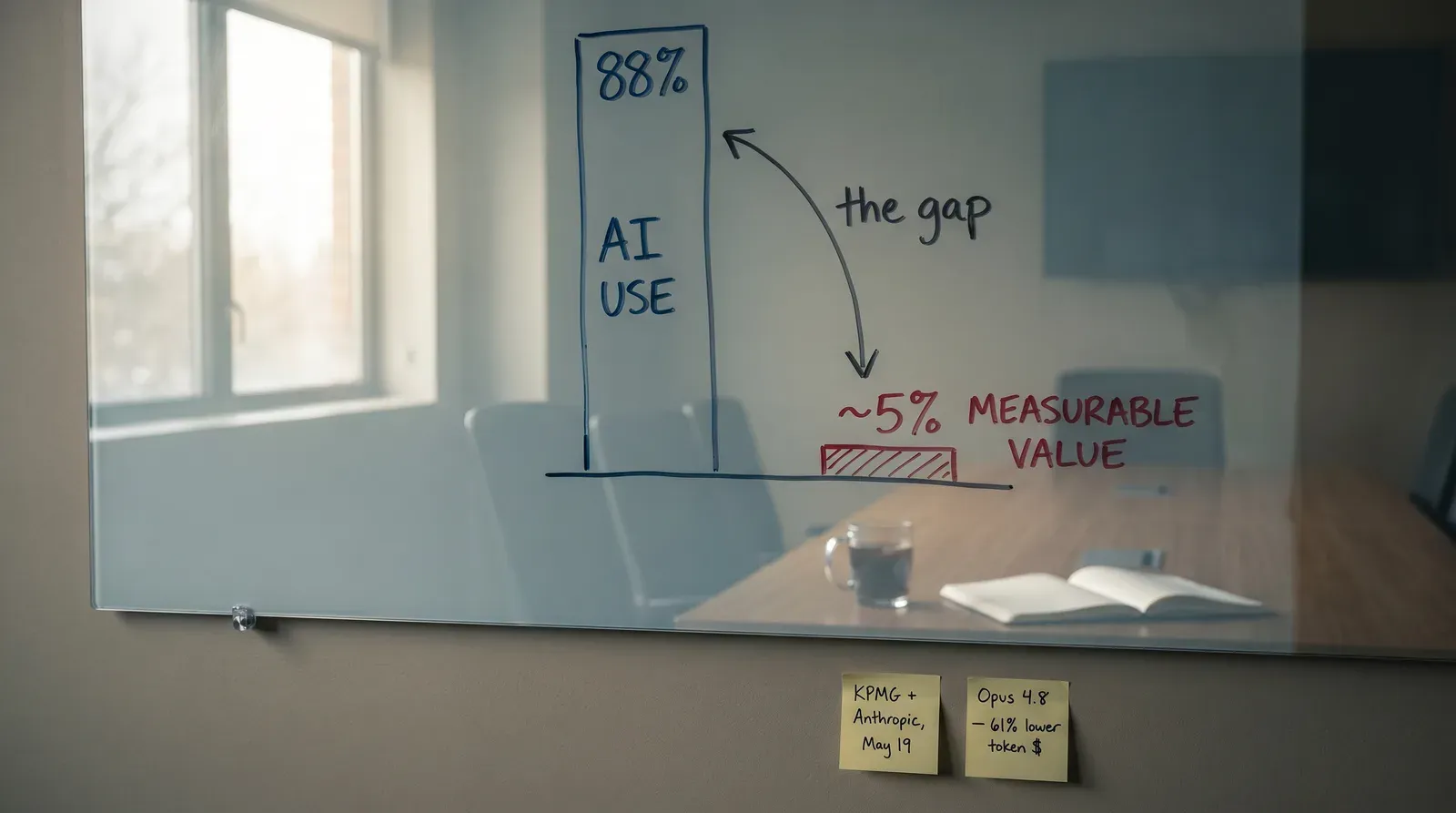
Cheaper Tokens Don't Close the Adoption-Value Gap
KPMG-Anthropic at workforce scale and Opus 4.8 at 61% lower token cost are real signals, not closure proof. The 88% vs ~5% gap lives at the outcome layer, not the input layer.
The market is reading two late-May announcements as proof that enterprise AI is finally crossing the value line. That read is too generous.
KPMG and Anthropic announced a broad alliance on May 19. Anthropic released Opus 4.8 on May 28, with Databricks framing one workload as 61% cheaper on token cost than Opus 4.7. Both are meaningful signals. Neither is evidence that the adoption-value gap has closed.
That gap is measured at the outcome layer. AIRS tracks the now-familiar split: ~88% AI use versus ~5% reporting measurable value. Those numbers are about frontline workflow change, customer-facing functionality, and unlocked capacity. They are not about seat count, model availability, or unit economics by token.
What the KPMG announcement does prove
The KPMG release gives us hard scope claims. Anthropic says KPMG is rolling Claude out to “276,000+” employees globally. Bill Thomas, Global Chairman and CEO of KPMG International, said the alliance reflects a commitment to responsible AI with security, trust, and governance as the firm scales capabilities for clients and employees. Rema Serafi, Vice Chair, Tax at KPMG US, made a specific workflow claim: an agent build for tax-regulation adjustment that used to take weeks now takes minutes inside Digital Gateway.
That is useful evidence. It proves deployment intent at workforce scale. It also proves tooling integration into real delivery environments, not sidecar experimentation.
It does not yet prove value capture at buyer-outcome level.
Why not? Because the announcement is still primarily seller-side evidence: rollout scale, platform integration, and speed-of-build claims. Those are leading indicators. They are not customer-outcome confirmation. We do not get named end-buyer statements with baseline-to-post metrics like reduced cost-to-serve, improved customer resolution, or measurable retention lift.
In short, KPMG gives us strong adoption evidence. It does not yet give us audited value evidence.
What the Opus 4.8 announcement does prove
Opus 4.8 adds real capability progress. Anthropic reports benchmark gains and a stronger reliability profile. Pricing for regular usage is unchanged from Opus 4.7, while fast mode is reported as three times cheaper than for previous models.
The most cited commercial line came from Hanlin Tang (Databricks), who said Opus 4.8 in Genie can reason over unstructured content at “61% cheaper token cost than Opus 4.7.”
That matters. Cost per unit of intelligence is a hard input into production economics.
It is still an input.
Token efficiency does not automatically produce enterprise value. Many organizations reduce model spend and still fail to move a frontline process. Others cut build time and still ship no customer-facing function that changes behavior. Lower unit cost improves the option set. It does not guarantee that leaders pick and operationalize the right option.
The Opus 4.8 page is also heavily builder and partner narrated. We see engineering teams and platform partners describing quality and performance lifts. We do not yet see a dense set of named buyer operators reporting post-deployment business outcomes with before-and-after measurement.
Again, this is good deployment signal. It is not closing-gap proof.
PwC is the right comparison, and the same boundary holds
The May 14 PwC-Anthropic expansion announcement is useful because it is more explicit about production posture. It claims active deployments across underwriting, modernization, HR transformation, and cybersecurity, with delivery improvements of up to 70%. It also names workforce-scale plans, including rollout to hundreds of thousands of professionals and training for 30,000 US professionals.
That is stronger than most vendor AI announcements.
But the evidence boundary is the same. Most of the claims are still partnership-side declarations in a joint release. We get one named client voice from Advocate Health, describing strategic intent and expected impact. We do not yet get a broad set of named buyer disclosures with standardized baseline, intervention, and measured outcome windows.
So the right reading is not “nothing is real.” The right reading is “the pipeline is real, outcome proof is still emerging.”
Two-pass discipline prevents category error
Pass 1 is where most people stop. They read rollout size, token price deltas, benchmark gains, and partner quotes. Then they infer value capture.
Pass 2 asks a harder question: where is T1 buyer evidence that the deployment moved an operating outcome?
For this news cluster, Pass 2 returns a mixed scorecard.
- We have T1 evidence of large-scale deployment intent and platform embedding.
- We have named executive claims on scope and workflow acceleration.
- We have partner-reported cost and performance improvements.
- We have limited named buyer outcome evidence with public baseline-to-post metrics.
That last line is where the adoption-value gap lives.
Until organizations publish outcome-layer evidence, “cheaper” and “bigger” remain necessary but insufficient.
What would count as real closure evidence
Three things would change the verdict fast.
First, named buyer disclosures with clear pre/post metrics tied to frontline workflows. Second, repeatability across sectors, not one flagship case. Third, durability over time, showing gains persist beyond pilot windows.
That is the AIRS lens. The outcome layer decides whether value is captured.
Cheaper tokens help. Workforce-scale rollouts help. Better models help.
None of those, on their own, close an 88% versus about 5% outcome gap.